This week Lytica began using new Lytica commodity names in our online Component Cost Estimator (CCE) product. In CCE, we will be displaying what we refer to as the Major Commodity name; the underlying construct consists of finer levels of granularity ranging from Super, Major, Sub and so on in order to classify the components. For some components, we may also show the sub commodity if it aids in classification recognition.
Aligned with the commodity designation is the component attribute, parametric and vertical market classification necessary to adequately define a device. The need for an adequate definition has been a focus of our AI enabled document reading technology as this ability to define is central to data organization, a problem that plagues many companies in our industry. When it comes to electronic components, there is little (if any) naming standardization. We have seen the same MPN labelled with many different commodity assignments. Some MPNs in our database have over 385 variations as submitted by customers, many of which are not even close to the correct part type.
There are rare occasions where clients want to use the commodity field in our benchmarking product to do more than analyse by part type. They may want to assess results by commodity teams or regions and, in these cases, they will use an appropriate designator as part of the commodity field. This substitution explains some of the variation we see but it’s a minimal driver of naming disparity.
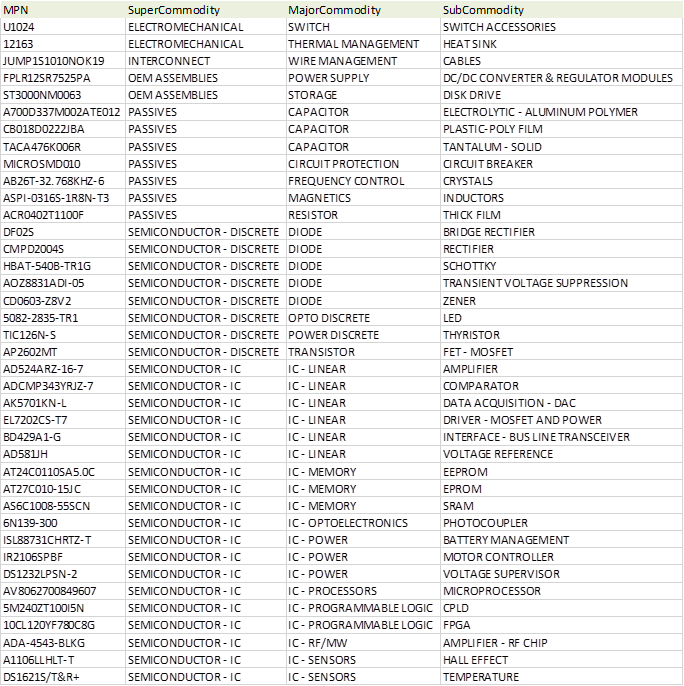
There is nothing truly unique in our commodity naming other than it is defined and uniformly applied across Lytica data as well for internal use of all data received from customers. This is a form of standardization which can now be found in CCE.
Our commodity naming convention presents all names in CAPITAL LETTERS and in either singular or plural format, as appropriate. A sample of our commodity naming is shown.
Data organization, consistency and quality are basic requirements for computer systems. Try searching for capacitors in a data set where the search field contains names like Capacitors, Capacitor, Caoacitosr, CAPS, MLCC, CAP, Resistor, PAS-CAP, socks and basketballs (to be extreme). Similarly, poor data quality also drives variation and hinders accurate outcomes as highlighted by the spelling error in Caoacitosr. Think of the time wasted trying to aggregate spending on capacitors without naming consistency.
New capabilities that we have developed are being tested internally at Lytica before being external released in our products. As stated in previous blogs, we are using AI technologies to improve our accuracy and productivity. We have developed information checkers, extraction applications and formatters to cleanse incoming data and are testing new algorithms. Tasks that took days have shrunk to seconds. These capabilities, along with the Lytica Commodity structure, will be introduced to Freebenchmarking.com and other new products this year so that we can enhance the user experience.
A definitive Lytica commodity naming convention is only one example of our data organization and normalization thrust. A focus on MPN cleansing and organisation, the management and accuracy of manufacturer names, standardized attribute and parametric presentation as well as the structure of other elements which users of e-components care about are also part of our mandate.
Carol Hamra is the VP of Operations & Engineering at Lytica Inc., a provider of supply chain analytics tools.
